Sematch is an integrated framework for the development, evaluation, and application of semantic similarity for Knowledge Graphs (KGs). It is easy to use Sematch to compute semantic similarity scores of concepts, words and entities. Sematch focuses on specific knowledge-based semantic similarity metrics that rely on structural knowledge in taxonomy (e.g. depth, path length, least common subsumer), and statistical information contents (corpus-IC and graph-IC). Knowledge-based approaches differ from their counterpart corpus-based approaches relying on co-occurrence (e.g. Pointwise Mutual Information) or distributional similarity (Latent Semantic Analysis, Word2Vec, GLOVE and etc). Knowledge-based approaches are usually used for structural KGs, while corpus-based approaches are normally applied in textual corpora.
In text analysis applications, a common pipeline is adopted in using semantic similarity from concept level, to word and sentence level. For example, word similarity is first computed based on similarity scores of WordNet concepts, and sentence similarity is computed by composing word similarity scores. Finally, document similarity could be computed by identifying important sentences, e.g. TextRank.
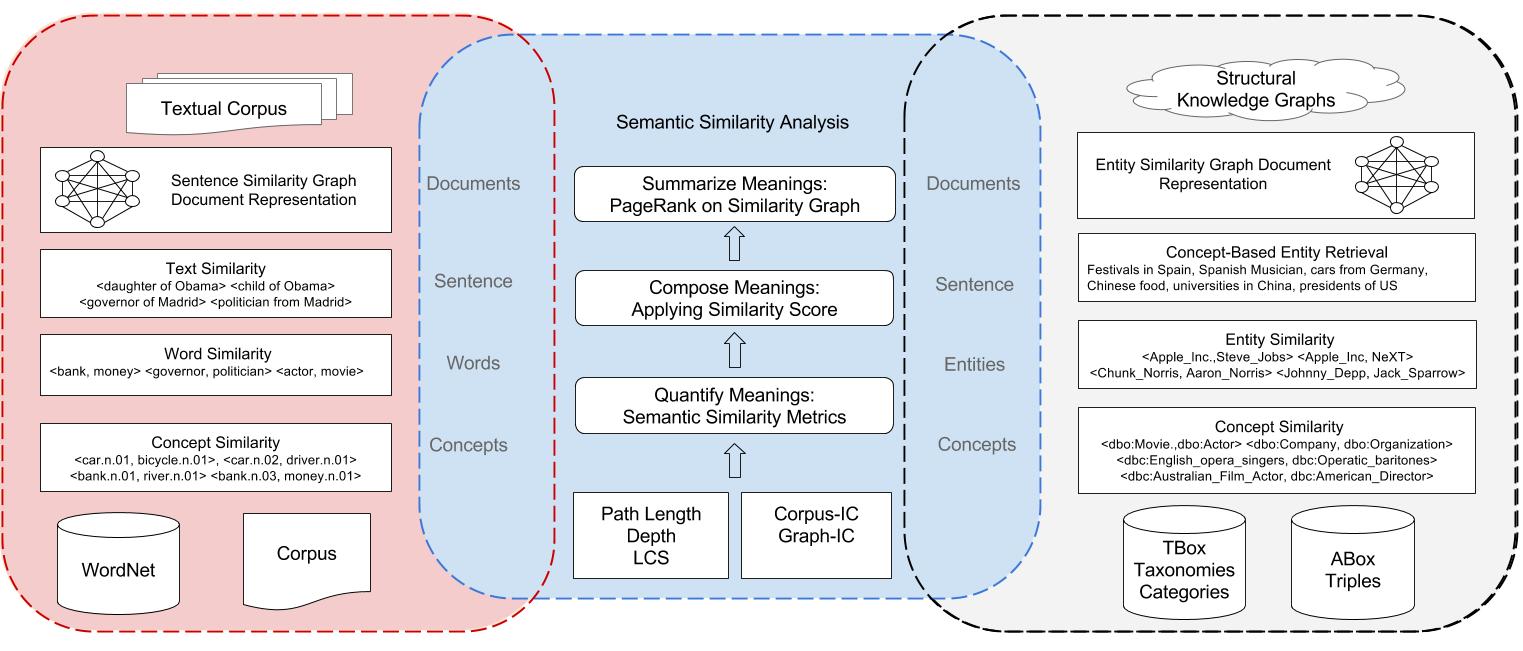
KG based applications also meet similar pipeline in using semantic similarity, from concept similarity (e.g. http://dbpedia.org/class/yago/Actor109765278) to entity similarity (e.g. http://dbpedia.org/resource/Madrid). Furthermore, in computing document similarity, entities are extracted and document similarity is computed by composing entity similarity scores.
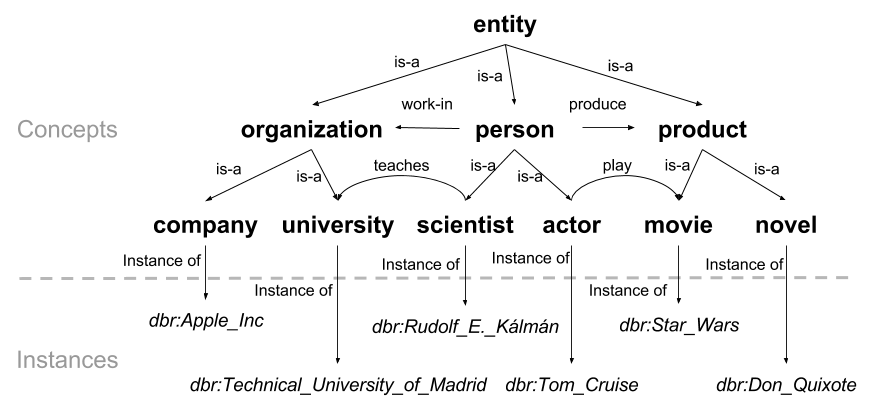
In KGs, concepts usually denote ontology classes while entities refer to ontology instances. Moreover, those concepts are usually constructed into hierarchical taxonomies, such as DBpedia ontology class, thus quantifying concept similarity in KG relies on similar semantic information (e.g. path length, depth, least common subsumer, information content) and semantic similarity metrics (e.g. Path, Wu & Palmer,Li, Resnik, Lin, Jiang & Conrad and WPath). In consequence, Sematch provides an integrated framework to develop and evaluate semantic similarity metrics for concepts, words, entities and their applications.
